- when there is clear separation between classes, the parameter estimates for the logic regression model can be surprisingly unstable, while discriminant approaches do not suffer
- If X is normal in each of the classes and the sample size is small, then discriminant approaches can be more accurate
Similar to MANOVA, let \(\mathbf_,\mathbf_,\dots, \mathbf_ \sim iid f_j (\mathbf)\) for \(j = 1,\dots, h\)
Let \(f_j(\mathbf)\) be the density function for population j . Note that each vector \(\mathbf\) contain measurements on all \(p\) traits
- Assume that each observation is from one of \(h\) possible populations.
- We want to form a discriminant rule that will allocate an observation \(\mathbf\) to population j when \(\mathbf\) is in fact from this population
22.4.1 Known Populations
The maximum likelihood discriminant rule for assigning an observation \(\mathbf\) to one of the \(h\) populations allocates \(\mathbf\) to the population that gives the largest likelihood to \(\mathbf\)
Consider the likelihood for a single observation \(\mathbf\) , which has the form \(f_j (\mathbf)\) where j is the true population.
Since \(j\) is unknown, to make the likelihood as large as possible, we should choose the value j which causes \(f_j (\mathbf)\) to be as large as possible
Consider a simple univariate example. Suppose we have data from one of two binomial populations.
- The first population has \(n= 10\) trials with success probability \(p = .5\)
- The second population has \(n= 10\) trials with success probability \(p = .7\)
- to which population would we assign an observation of \(y = 7\)
- Note:
- \(f(y = 7|n = 10, p = .5) = .117\)
- \(f(y = 7|n = 10, p = .7) = .267\) where \(f(.)\) is the binomial likelihood.
- Hence, we choose the second population
We have 2 populations, where
- First population: \(N(\mu_1, \sigma^2_1)\)
- Second population: \(N(\mu_2, \sigma^2_2)\)
The likelihood for a single observation is
Consider a likelihood ratio rule
Hence, we classify into
- pop 1 if \(\Lambda >1\)
- pop 2 if \(\Lambda
- for ties, flip a coin
Another way to think:
we classify into population 1 if the “standardized distance” of y from \(\mu_1\) is less than the “standardized distance” of y from \(\mu_2\) which is referred to as a quadratic discriminant rule.
(Significant simplification occurs in th special case where \(\sigma_1 = \sigma_2 = \sigma^2\) )
Thus, we classify into population 1 if
\[ (y - \mu_2)^2 > (y - \mu_1)^2 \]
\[ |y- \mu_2| > |y - \mu_1| \]
Thus, we classify into population 1 if this is less than 0.
Discriminant classification rule is linear in y in this case.
22.4.1.1 Multivariate Expansion
Suppose that there are 2 populations
- \(N_p(\mathbf<\mu>_1, \mathbf_1)\)
- \(N_p(\mathbf<\mu>_2, \mathbf_2)\)
Again, we classify into population 1 if this is less than 0, otherwise, population 2. And like the univariate case with non-equal variances, this is a quadratic discriminant rule.
And if the covariance matrices are equal: \(\mathbf_1 = \mathbf_2 = \mathbf_1\) classify into population 1 if
\[ (\mathbf<\mu>_1 - \mathbf<\mu>_2)' \mathbf^\mathbf - \frac (\mathbf<\mu>_1 - \mathbf<\mu>_2)' \mathbf^ (\mathbf<\mu>_1 - \mathbf<\mu>_2) \ge 0 \]
This linear discriminant rule is also referred to as Fisher’s linear discriminant function
By assuming the covariance matrices are equal, we assume that the shape and orientation fo the two populations must be the same (which can be a strong restriction)
In other words, for each variable, it can have different mean but the same variance.
- Note: LDA Bayes decision boundary is linear. Hence, quadratic decision boundary might lead to better classification. Moreover, the assumption of same variance/covariance matrix across all classes for Gaussian densities imposes the linear rule, if we allow the predictors in each class to follow MVN distribution with class-specific mean vectors and variance/covariance matrices, then it is Quadratic Discriminant Analysis. But then, you will have more parameters to estimate (which gives more flexibility than LDA) at the cost of more variance (bias -variance tradeoff).
When \(\mathbf<\mu>_1, \mathbf<\mu>_2, \mathbf\) are known, the probability of misclassification can be determined:
- \(\delta^2 = (\mathbf<\mu>_1 - \mathbf<\mu>_2)' \mathbf^ (\mathbf<\mu>_1 - \mathbf<\mu>_2)\)
- \(\Phi\) is the standard normal CDF
Suppose there are \(h\) possible populations, which are distributed as \(N_p (\mathbf<\mu>_p, \mathbf)\) . Then, the maximum likelihood (linear) discriminant rule allocates \(\mathbf\) to population j where j minimizes the squared Mahalanobis distance
22.4.1.2 Bayes Discriminant Rules
If we know that population j has prior probabilities \(\pi_j\) (assume \(\pi_j >0\) ) we can form the Bayes discriminant rule.
This rule allocates an observation \(\mathbf\) to the population for which \(\pi_j f_j (\mathbf)\) is maximized.
- Maximum likelihood discriminant rule is a special case of the Bayes discriminant rule, where it sets all the \(\pi_j = 1/h\)
Optimal Properties of Bayes Discriminant Rules
- let \(p_\) be the probability of correctly assigning an observation from population i
- then one rule (with probabilities \(p_\) ) is as good as another rule (with probabilities \(p_'\) ) if \(p_ \ge p_'\) for all \(i = 1,\dots, h\)
- The first rule is better than the alternative if \(p_ > p_'\) for at least one i.
- A rule for which there is no better alternative is called admissible
- Bayes Discriminant Rules are admissible
- If we utilized prior probabilities, then we can form the posterior probability of a correct allocation, \(\sum_^h \pi_i p_\)
- Bayes Discriminant Rules have the largest possible posterior probability of correct allocation with respect to the prior
- These properties show that Bayes Discriminant rule is our best approach.
- We want to consider the cost misallocation
- Define \(c_\) to be the cost associated with allocation a member of population j to population i.
- \(c_ >0\) for all \(i \neq j\)
- \(c_ = 0\) if \(i = j\)
Example:
Two binomial populations, each of size 10, with probabilities \(p_1 = .5\) and \(p_2 = .7\)
And the probability of being in the first population is .9
However, suppose the cost of inappropriately allocating into the first population is 1 and the cost of incorrectly allocating into the second population is 5.
In this case, we pick population 1 over population 2
In general, we consider two regions, \(R_1\) and \(R_2\) associated with population 1 and 2:
where \(c_\) is the cost of assigning a member of population 2 to population 1.
22.4.1.3 Discrimination Under Estimation
Suppose we know the form of the distributions for populations of interests, but we still have to estimate the parameters.
we know the distributions are multivariate normal, but we have to estimate the means and variances
The maximum likelihood discriminant rule allocates an observation \(\mathbf\) to population j when j maximizes the function
where \(\hat\) are the maximum likelihood estimates of the unknown parameters
For instance, we have 2 multivariate normal populations with distinct means, but common variance covariance matrix
MLEs for \(\mathbf<\mu>_1\) and \(\mathbf<\mu>_2\) are \(\mathbf>_1\) and \(\mathbf>_2\) and common \(\mathbf\) is \(\mathbf\) .
Thus, an estimated discriminant rule could be formed by substituting these sample values for the population values
22.4.1.4 Native Bayes
- The challenge with classification using Bayes’ is that we don’t know the (true) densities, \(f_k, k = 1, \dots, K\) , while LDA and QDA make strong multivariate normality assumptions to deal with this.
- Naive Bayes makes only one assumption: within the k-th class, the p predictors are independent (i.e,, for \(k = 1,\dots, K\)
\[ f_k(x) = f_(x_1) \times f_(x_2) \times \dots \times f_(x_p) \]
where \(f_\) is the density function of the j-th predictor among observation in the k-th class.
This assumption allows the use of joint distribution without the need to account for dependence between observations. However, this (native) assumption can be unrealistic, but still works well in cases where the number of sample (n) is not large relative to the number of features (p).
With this assumption, we have
\[ P(Y=k|X=x) = \frac<\pi_k \times f_
(x_1) \times \dots \times f_(x_p)>^K \pi_l \times f_(x_1)\times \dots f_(x_p)> \] we only need to estimate the one-dimensional density function \(f_\) with either of these approaches:
- When \(X_j\) is quantitative, assume it has a univariate normal distribution (with independence): \(X_j | Y = k \sim N(\mu_, \sigma^2_)\) which is more restrictive than QDA because it assumes predictors are independent (e.g., a diagonal covariance matrix)
- When \(X_j\) is quantitative, use a kernel density estimator Kernel Methods ; which is a smoothed histogram
- When \(X_j\) is qualitative, we count the promotion of training observations for the j-th predictor corresponding to each class.
22.4.1.5 Comparison of Classification Methods
Assuming we have K classes and K is the baseline from (James , Witten, Hastie, and Tibshirani book)
Comparing the log odds relative to the K class
22.4.1.5.1 Logistic Regression
22.4.1.5.2 LDA
where \(a_k\) and \(b_\) are functions of \(\pi_k, \pi_K, \mu_k , \mu_K, \mathbf\)
Similar to logistic regression, LDA assumes the log odds is linear in \(x\)
Even though they look like having the same form, the parameters in logistic regression are estimated by MLE, where as LDA linear parameters are specified by the prior and normal distributions
We expect LDA to outperform logistic regression when the normality assumption (approximately) holds, and logistic regression to perform better when it does not
22.4.1.5.3 QDA
where \(a_k, b_, c_\) are functions \(\pi_k , \pi_K, \mu_k, \mu_K ,\mathbf_k, \mathbf_K\)
22.4.1.5.4 Naive Bayes
where \(a_k = \log (\pi_k / \pi_K)\) and \(g_(x_j) = \log(\frac
22.4.1.5.5 Summary
- LDA is a special case of QDA
- LDA is robust when it comes to high dimensions
- Any classifier with a linear decision boundary is a special case of naive Bayes with \(g_(x_j) = b_ x_j\) , which means LDA is a special case of naive Bayes. LDA assumes that the features are normally distributed with a common within-class covariance matrix, and naive Bayes assumes independence of the features.
- Naive bayes is also a special case of LDA with \(\mathbf\) restricted to a diagonal matrix with diagonals, \(\sigma^2\) (another notation \(diag (\mathbf)\) ) assuming \(f_(x_j) = N(\mu_, \sigma^2_j)\)
- QDA and naive Bayes are not special case of each other. In principal,e naive Bayes can produce a more flexible fit by the choice of \(g_(x_j)\) , but it’s restricted to only purely additive fit, but QDA includes multiplicative terms of the form \(c_x_j x_l\)
- None of these methods uniformly dominates the others: the choice of method depends on the true distribution of the predictors in each of the K classes, n and p (i.e., related to the bias-variance tradeoff).
Compare to the non-parametric method (KNN)
- KNN would outperform both LDA and logistic regression when the decision boundary is highly nonlinear, but can’t say which predictors are most important, and requires many observations
- KNN is also limited in high-dimensions due to the curse of dimensionality
- Since QDA is a special type of nonlinear decision boundary (quadratic), it can be considered as a compromise between the linear methods and KNN classification. QDA can have fewer training observations than KNN but not as flexible.
True decision boundary Best performance Linear LDA + Logistic regression Moderately nonlinear QDA + Naive Bayes Highly nonlinear (many training, p is not large) KNN - like linear regression, we can also introduce flexibility by including transformed features \(\sqrt, X^2, X^3\)
22.4.2 Probabilities of Misclassification
When the distribution are exactly known, we can determine the misclassification probabilities exactly. however, when we need to estimate the population parameters, we have to estimate the probability of misclassification
- Naive method
- Plugging the parameters estimates into the form for the misclassification probabilities results to derive at the estimates of the misclassification probability.
- But this will tend to be optimistic when the number of samples in one or more populations is small.
- Use the proportion of the samples from population i that would be allocated to another population as an estimate of the misclassification probability
- But also optimistic when the number of samples is small
- The above two methods use observation to estimate both parameters and also misclassification probabilities based upon the discriminant rule
- Alternatively, we determine the discriminant rule based upon all of the data except the k-th observation from the j-th population
- then, determine if the k-th observation would be misclassified under this rule
- perform this process for all \(n_j\) observation in population j . An estimate fo the misclassification probability would be the fraction of \(n_j\) observations which were misclassified
- repeat the process for other \(i \neq j\) populations
- This method is more reliable than the others, but also computationally intensive
Summary
Consider the group-specific densities \(f_j (\mathbf)\) for multivariate vector \(\mathbf\) .
Assume equal misclassifications costs, the Bayes classification probability of \(\mathbf\) belonging to the j-th population is
where there are \(h\) possible groups.
We then classify into the group for which this probability of membership is largest
Alternatively, we can write this in terms of a generalized squared distance formation
\[ D_j^2 (\mathbf) = d_j^2 (\mathbf)+ g_1(j) + g_2 (j) \]
- \(d_j^2(\mathbf) = (\mathbf - \mathbf<\mu>_j)' \mathbf_j^ (\mathbf - \mathbf<\mu>_j)\) is the squared Mahalanobis distance from \(\mathbf\) to the centroid of group j, and
- \(\mathbf_j = \mathbf_j\) if the within group covariance matrices are not equal
- \(\mathbf_j = \mathbf_p\) if a pooled covariance estimate is appropriate
then, the posterior probability of belonging to group j is
where \(j = 1,\dots , h\)
and \(\mathbf\) is classified into group j if \(p(j | \mathbf)\) is largest for \(j = 1,\dots,h\) (or, \(D_j^2(\mathbf)\) is smallest).
22.4.2.1 Assessing Classification Performance
For binary classification, confusion matrix
Predicted class - or Null + or Null Total True Class - or Null True Neg (TN) False Pos (FP) N + or Null False Neg (FN) True Pos (TP) P Total N* P* Name Definition Synonyms False Pos rate FP/N Type I error, 1 0 Specificity True Pos. rate TP/P 1 - Type II error, power, sensitivity, recall Pos Pred. value TP/P* Precision, 1 - false discovery promotion Neg. Pred. value TN/N* ROC curve (receiver Operating Characteristics) is a graphical comparison between sensitivity (true positive) and specificity ( = 1 - false positive)
y-axis = true positive rate
x-axis = false positive rate
as we change the threshold rate for classifying an observation as from 0 to 1
AUC (area under the ROC) ideally would equal to 1, a bad classifier would have AUC = 0.5 (pure chance)
22.4.3 Unknown Populations/ Nonparametric Discrimination
When your multivariate data are not Gaussian, or known distributional form at all, we can use the following methods
22.4.3.1 Kernel Methods
We approximate \(f_j (\mathbf)\) by a kernel density estimate
- \(K_j (.)\) is a kernel function satisfying \(\int K_j(\mathbf)d\mathbf =1\)
- \(\mathbf_i\) , \(i = 1,\dots , n_j\) is a random sample from the j-th population.
Thus, after finding \(\hat_j (\mathbf)\) for each of the \(h\) populations, the posterior probability of group membership is
where \(j = 1,\dots, h\)
There are different choices for the kernel function:
- Uniform
- Normal
- Epanechnikov
- Biweight
- Triweight
We these kernels, we have to pick the “radius” (or variance, width, window width, bandwidth) of the kernel, which is a smoothing parameter (the larger the radius, the more smooth the kernel estimate of the density).
To select the smoothness parameter, we can use the following method
If we believe the populations were close to multivariate normal, then
But since we do not know for sure, we might choose several different values and select one that vies the best out of sample or cross-validation discrimination.
Moreover, you also have to decide whether to use different kernel smoothness for different populations, which is similar to the individual and pooled covariances in the classical methodology.
22.4.3.2 Nearest Neighbor Methods
The nearest neighbor (also known as k-nearest neighbor) method performs the classification of a new observation vector based on the group membership of its nearest neighbors. In practice, we find
\[ d_^2 (\mathbf, \mathbf_i) = (\mathbf, \mathbf_i) V_j^(\mathbf, \mathbf_i) \]
which is the distance between the vector \(\mathbf\) and the \(i\) -th observation in group \(j\)
We consider different choices for \(\mathbf_j\)
\[ \begin \mathbf_j &= \mathbf_p \\ \mathbf_j &= \mathbf_j \\ \mathbf_j &= \mathbf \\ \mathbf_j &= diag (\mathbf_p) \end \]
We find the \(k\) observations that are closest to \(\mathbf\) (where users pick \(k\) ). Then we classify into the most common population, weighted by the prior.
22.4.3.3 Modern Discriminant Methods
Note:
Logistic regression (with or without random effects) is a flexible model-based procedure for classification between two populations.
The extension of logistic regression to the multi-group setting is polychotomous logistic regression (or, mulinomial regression).
The machine learning and pattern recognition are growing with strong focus on nonlinear discriminant analysis methods such as:
- radial basis function networks
- support vector machines
- multiplayer perceptrons (neural networks)
The general framework
\[ g_j (\mathbf) = \sum_^m w_\phi_l (\mathbf; \mathbf_l) + w_ \]
- \(j = 1,\dots, h\)
- \(m\) nonlinear basis functions \(\phi_l\) , each of which has \(n_m\) parameters given by \(\theta_l = \< \theta_: k = 1, \dots , n_m \>\)
We assign \(\mathbf\) to the \(j\) -th population if \(g_j(\mathbf)\) is the maximum for all \(j = 1,\dots, h\)
Development usually focuses on the choice and estimation of the basis functions, \(\phi_l\) and the estimation of the weights \(w_\)
22.4.4 Application
library(class) library(klaR) library(MASS) library(tidyverse) ## Read in the data crops read.table("images/crops.txt") names(crops) c("crop", "y1", "y2", "y3", "y4") str(crops) #> 'data.frame': 36 obs. of 5 variables: #> $ crop: chr "Corn" "Corn" "Corn" "Corn" . #> $ y1 : int 16 15 16 18 15 15 12 20 24 21 . #> $ y2 : int 27 23 27 20 15 32 15 23 24 25 . #> $ y3 : int 31 30 27 25 31 32 16 23 25 23 . #> $ y4 : int 33 30 26 23 32 15 73 25 32 24 . ## Read in test data crops_test read.table("images/crops_test.txt") names(crops_test) c("crop", "y1", "y2", "y3", "y4") str(crops_test) #> 'data.frame': 5 obs. of 5 variables: #> $ crop: chr "Corn" "Soybeans" "Cotton" "Sugarbeets" . #> $ y1 : int 16 21 29 54 32 #> $ y2 : int 27 25 24 23 32 #> $ y3 : int 31 23 26 21 62 #> $ y4 : int 33 24 28 54 1622.4.4.1 LDA
Default prior is proportional to sample size and lda and qda do not fit a constant or intercept term
## Linear discriminant analysis lda_mod lda(crop ~ y1 + y2 + y3 + y4, data = crops) lda_mod #> Call: #> lda(crop ~ y1 + y2 + y3 + y4, data = crops) #> #> Prior probabilities of groups: #> Clover Corn Cotton Soybeans Sugarbeets #> 0.3055556 0.1944444 0.1666667 0.1666667 0.1666667 #> #> Group means: #> y1 y2 y3 y4 #> Clover 46.36364 32.63636 34.18182 36.63636 #> Corn 15.28571 22.71429 27.42857 33.14286 #> Cotton 34.50000 32.66667 35.00000 39.16667 #> Soybeans 21.00000 27.00000 23.50000 29.66667 #> Sugarbeets 31.00000 32.16667 20.00000 40.50000 #> #> Coefficients of linear discriminants: #> LD1 LD2 LD3 LD4 #> y1 -6.147360e-02 0.009215431 -0.02987075 -0.014680566 #> y2 -2.548964e-02 0.042838972 0.04631489 0.054842132 #> y3 1.642126e-02 -0.079471595 0.01971222 0.008938745 #> y4 5.143616e-05 -0.013917423 0.05381787 -0.025717667 #> #> Proportion of trace: #> LD1 LD2 LD3 LD4 #> 0.7364 0.1985 0.0576 0.0075 ## Look at accuracy on the training data lda_fitted predict(lda_mod,newdata = crops) # Contingency table lda_table table(truth = crops$crop, fitted = lda_fitted$class) lda_table #> fitted #> truth Clover Corn Cotton Soybeans Sugarbeets #> Clover 6 0 3 0 2 #> Corn 0 6 0 1 0 #> Cotton 3 0 1 2 0 #> Soybeans 0 1 1 3 1 #> Sugarbeets 1 1 0 2 2 # accuracy of 0.5 is just random (not good) ## Posterior probabilities of membership crops_post cbind.data.frame(crops, crop_pred = lda_fitted$class, lda_fitted$posterior) crops_post crops_post %>% mutate(missed = crop != crop_pred) head(crops_post) #> crop y1 y2 y3 y4 crop_pred Clover Corn Cotton Soybeans #> 1 Corn 16 27 31 33 Corn 0.08935164 0.4054296 0.1763189 0.2391845 #> 2 Corn 15 23 30 30 Corn 0.07690181 0.4558027 0.1420920 0.2530101 #> 3 Corn 16 27 27 26 Corn 0.09817815 0.3422454 0.1365315 0.3073105 #> 4 Corn 18 20 25 23 Corn 0.10521511 0.3633673 0.1078076 0.3281477 #> 5 Corn 15 15 31 32 Corn 0.05879921 0.5753907 0.1173332 0.2086696 #> 6 Corn 15 32 32 15 Soybeans 0.09723648 0.3278382 0.1318370 0.3419924 #> Sugarbeets missed #> 1 0.08971545 FALSE #> 2 0.07219340 FALSE #> 3 0.11573442 FALSE #> 4 0.09546233 FALSE #> 5 0.03980738 FALSE #> 6 0.10109590 TRUE # posterior shows that posterior of corn membership is much higher than the prior ## LOOCV # leave-one-out cross validation for linear discriminant analysis # cannot run the predict function using the object with CV = TRUE # because it returns the within sample predictions lda_cv lda(crop ~ y1 + y2 + y3 + y4, data = crops, CV = TRUE) # Contingency table lda_table_cv table(truth = crops$crop, fitted = lda_cv$class) lda_table_cv #> fitted #> truth Clover Corn Cotton Soybeans Sugarbeets #> Clover 4 3 1 0 3 #> Corn 0 4 1 2 0 #> Cotton 3 0 0 2 1 #> Soybeans 0 1 1 3 1 #> Sugarbeets 2 1 0 2 1 ## Predict the test data lda_pred predict(lda_mod, newdata = crops_test) ## Make a contingency table with truth and most likely class table(truth=crops_test$crop, predict=lda_pred$class) #> predict #> truth Clover Corn Cotton Soybeans Sugarbeets #> Clover 0 0 1 0 0 #> Corn 0 1 0 0 0 #> Cotton 0 0 0 1 0 #> Soybeans 0 0 0 1 0 #> Sugarbeets 1 0 0 0 0LDA didn’t do well on both within sample and out-of-sample data.
22.4.4.2 QDA
## Quadratic discriminant analysis qda_mod qda(crop ~ y1 + y2 + y3 + y4, data = crops) ## Look at accuracy on the training data qda_fitted predict(qda_mod, newdata = crops) # Contingency table qda_table table(truth = crops$crop, fitted = qda_fitted$class) qda_table #> fitted #> truth Clover Corn Cotton Soybeans Sugarbeets #> Clover 9 0 0 0 2 #> Corn 0 7 0 0 0 #> Cotton 0 0 6 0 0 #> Soybeans 0 0 0 6 0 #> Sugarbeets 0 0 1 1 4 ## LOOCV qda_cv qda(crop ~ y1 + y2 + y3 + y4, data = crops, CV = TRUE) # Contingency table qda_table_cv table(truth = crops$crop, fitted = qda_cv$class) qda_table_cv #> fitted #> truth Clover Corn Cotton Soybeans Sugarbeets #> Clover 9 0 0 0 2 #> Corn 3 2 0 0 2 #> Cotton 3 0 2 0 1 #> Soybeans 3 0 0 2 1 #> Sugarbeets 3 0 1 1 1 ## Predict the test data qda_pred predict(qda_mod, newdata = crops_test) ## Make a contingency table with truth and most likely class table(truth = crops_test$crop, predict = qda_pred$class) #> predict #> truth Clover Corn Cotton Soybeans Sugarbeets #> Clover 1 0 0 0 0 #> Corn 0 1 0 0 0 #> Cotton 0 0 1 0 0 #> Soybeans 0 0 0 1 0 #> Sugarbeets 0 0 0 0 122.4.4.3 KNN
knn uses design matrices of the features.
## Design matrices X_train crops %>% dplyr::select(-crop) X_test crops_test %>% dplyr::select(-crop) Y_train crops$crop Y_test crops_test$crop ## Nearest neighbors with 2 neighbors knn_2 knn(X_train, X_train, Y_train, k = 2) table(truth = Y_train, fitted = knn_2) #> fitted #> truth Clover Corn Cotton Soybeans Sugarbeets #> Clover 7 0 2 1 1 #> Corn 0 7 0 0 0 #> Cotton 0 0 4 0 2 #> Soybeans 0 0 0 4 2 #> Sugarbeets 1 0 2 0 3 ## Accuracy mean(Y_train==knn_2) #> [1] 0.6944444 ## Performance on test data knn_2_test knn(X_train, X_test, Y_train, k = 2) table(truth = Y_test, predict = knn_2_test) #> predict #> truth Clover Corn Cotton Soybeans Sugarbeets #> Clover 1 0 0 0 0 #> Corn 0 1 0 0 0 #> Cotton 0 0 0 0 1 #> Soybeans 0 0 0 1 0 #> Sugarbeets 0 0 0 0 1 ## Accuracy mean(Y_test==knn_2_test) #> [1] 0.8 ## Nearest neighbors with 3 neighbors knn_3 knn(X_train, X_train, Y_train, k = 3) table(truth = Y_train, fitted = knn_3) #> fitted #> truth Clover Corn Cotton Soybeans Sugarbeets #> Clover 8 0 1 1 1 #> Corn 0 4 1 2 0 #> Cotton 1 1 3 0 1 #> Soybeans 0 1 1 4 0 #> Sugarbeets 0 0 0 2 4 ## Accuracy mean(Y_train==knn_3) #> [1] 0.6388889 ## Performance on test data knn_3_test knn(X_train, X_test, Y_train, k = 3) table(truth = Y_test, predict = knn_3_test) #> predict #> truth Clover Corn Cotton Soybeans Sugarbeets #> Clover 1 0 0 0 0 #> Corn 0 1 0 0 0 #> Cotton 0 0 1 0 0 #> Soybeans 0 0 0 1 0 #> Sugarbeets 0 0 0 0 1 ## Accuracy mean(Y_test==knn_3_test) #> [1] 122.4.4.4 Stepwise
Stepwise discriminant analysis using the stepclass in function in the klaR package.
step stepclass( crop ~ y1 + y2 + y3 + y4, data = crops, method = "qda", improvement = 0.15 ) #> correctness rate: 0.45; in: "y1"; variables (1): y1 #> #> hr.elapsed min.elapsed sec.elapsed #> 0.00 0.00 0.16 step$process #> step var varname result.pm #> 0 start 0 -- 0.00 #> 1 in 1 y1 0.45 step$performance.measure #> [1] "correctness rate"library(dplyr) data('iris') set.seed(1) samp sample.int(nrow(iris), size = floor(0.70 * nrow(iris)), replace = F) train.iris iris[samp,] %>% mutate_if(is.numeric,scale) test.iris iris[-samp,] %>% mutate_if(is.numeric,scale) library(ggplot2) iris.model lda(Species ~ ., data = train.iris) #pred pred.lda predict(iris.model, test.iris) table(truth = test.iris$Species, prediction = pred.lda$class) #> prediction #> truth setosa versicolor virginica #> setosa 15 0 0 #> versicolor 0 17 0 #> virginica 0 0 13 plot(iris.model)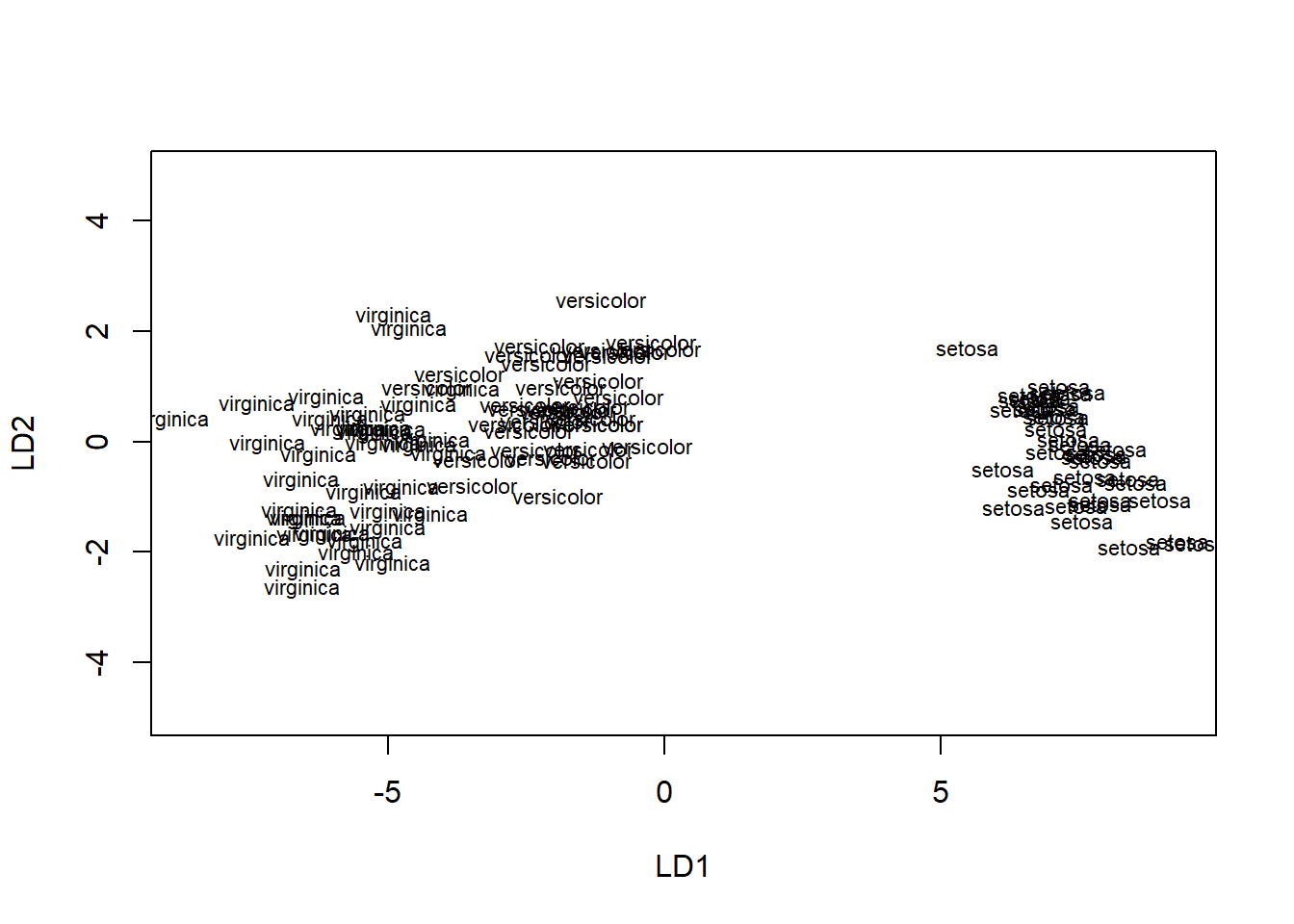
iris.model.qda qda(Species~.,data=train.iris) #pred pred.qda predict(iris.model.qda,test.iris) table(truth=test.iris$Species,prediction=pred.qda$class) #> prediction #> truth setosa versicolor virginica #> setosa 15 0 0 #> versicolor 0 16 1 #> virginica 0 0 1322.4.4.5 PCA with Discriminant Analysis
we can use both PCA for dimension reduction in discriminant analysis
zeros as.matrix(read.table("images/mnist0_train_b.txt")) nines as.matrix(read.table("images/mnist9_train_b.txt")) train rbind(zeros[1:1000, ], nines[1:1000, ]) train train / 255 #divide by 255 per notes (so ranges from 0 to 1) train t(train) #each column is an observation image(matrix(train[, 1], nrow = 28), main = 'Example image, unrotated')
test rbind(zeros[2501:3000, ], nines[2501:3000, ]) test test / 255 test t(test) y.train c(rep(0, 1000), rep(9, 1000)) y.test c(rep(0, 500), rep(9, 500)) library(MASS) pc prcomp(t(train)) train.large data.frame(cbind(y.train, pc$x[, 1:10])) large lda(y.train ~ ., data = train.large) #the test data set needs to be constucted w/ the same 10 princomps test.large data.frame(cbind(y.test, predict(pc, t(test))[, 1:10])) pred.lda predict(large, test.large) table(truth = test.large$y.test, prediction = pred.lda$class) #> prediction #> truth 0 9 #> 0 491 9 #> 9 5 495 large.qda qda(y.train~.,data=train.large) #prediction pred.qda predict(large.qda,test.large) table(truth=test.large$y.test,prediction=pred.qda$class) #> prediction #> truth 0 9 #> 0 493 7 #> 9 3 497References
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2013. An Introduction to Statistical Learning. Vol. 112. Springer.
Webb, Andrew R, Keith D Copsey, and Gavin Cawley. 2011. Statistical Pattern Recognition. Vol. 2. Wiley Online Library.
